
同步应用程序(应用程序.同步...)

单体应用程序是一种软件,其中系统的所有组件(例如用户界面、业务逻辑和数据库)都集成到一个统一的结构中。在此架构中,所有组件都作为一个应用程序的一部分运行。 单体应用程序的特点...
Python 中的这种运行时元编程模式很有趣(很有趣.运行.编程.模式.Python...)
背景 我目前正在开发一个基于 pyodide 的 ui 框架,称为 zenaura。最近,我注意到构建器界面(用户创建 ui 元素的主要方式)有点过于复杂且没有吸引力。虽然它确实抽象了底层的、更麻...
java sprict有何工具支持(有何.支持.工具.java.sprict...)

Spring框架为Java开发者提供了强大的工具集,显著提升开发效率并简化流程,尤其适用于企业级应用开发。 以下是Spring框架提供的关键工具: 核心工具支持:强大的断言工具: Spring B...
html里如何加入php(html.php...)

要将 php 代码添加到 html 中,需要使用 php 标签()。具体步骤包括:1. 打开 html 文档;2. 在所需位置插入 php 起始标签()。如何将 PHP 添加到 HTML 中 在 HT...
如何使用 Scrapy Xpath 获取 div 标签下的完整 HTML 内容?(如何使用.获取.完整.标签.内容...)

如何用 scrapy xpath 获取指定标签下的完整 html 内容? 给定以下 html 片段: <div class="contson"> 这是文本...
## 使用 Selenium 遍历多个元素时遇到“无法解包不可迭代的 WebElement 对象”错误怎么办?(多个.遍历.元素.对象.错误...)

python 报错:“无法解包不可迭代的 webelement 对象” 在使用 selenium 库的 find_elements_by_css_selector 方法获取多个元素并进行遍历时,您...
如何使用setuptools让Python脚本通过pip安装后生成可执行文件?(如何使用.脚本.可执行文件.生成.安装...)
python脚本和pip集成:如何在pip安装后生成可执行文件 在python开发中,通过pip安装库后可以在当前环境的bin目录下生成可执行文件,简化脚本的执行。例如,pip安装flask或dja...
Pokémon Info Retriever: A Fun and Educational Project(Retriever.Info.Pok.Project.Educational...)
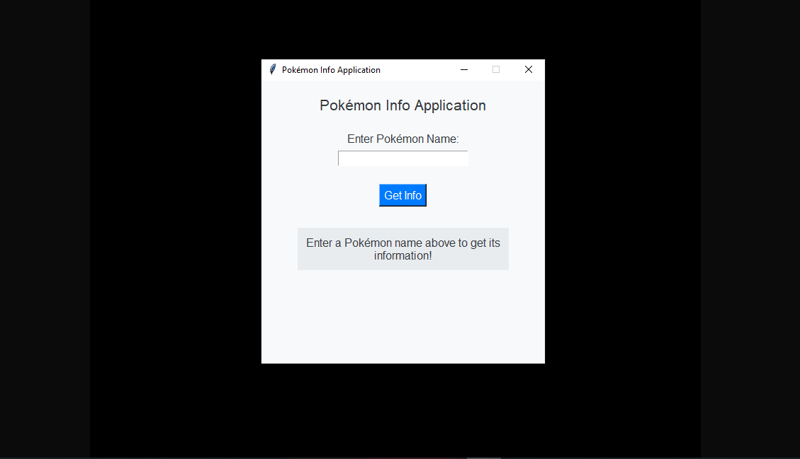
作为一名充满热情的软件开发人员,我踏上了创建 pokémon info retriever 应用程序的激动人心的旅程。该项目结合了多种技术,为用户提供使用 pokeapi 访问详细 pokémon 信...
Python 库安装失败怎么办? - 解决 Slate 和 PDFMiner 安装问题(安装.失败.解决.Python.Slate...)

Python 库安装常见问题 您在尝试安装 slate 和 pdfminer 时遇到了一些困难。这些库通常需要在国外网站上下载和安装。以下是解决这些问题的常见方法: 对于 conda 安装失败的问题...
Python3 如何将列表中多个字符串字典合并为一个字典?(字典.多个.并为.字符串.如何将...)

python3 如何将列表中多个字典值合并为一个字典 要将包含多个字典的列表合并为一个字典,需要使用 [json.loads()](https://docs.python.org/3/library...