
使用 DevTools 和 HAR 文件抓取数据(抓取.文件.数据.DevTools.HAR...)
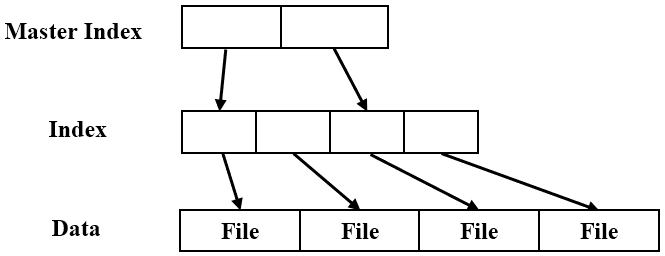
数据抓取:高效获取blinkit产品数据,助力应用开发 对于构建应用需要真实数据的开发者来说,数据抓取是高效获取信息的关键。本文将分享如何利用Chrome DevTools和HAR文件从Blinkit...
使用 Beautiful Soup 和 Scrapy 进行网页抓取:高效、负责任地提取数据(高效.抓取.负责任.提取.网页...)

在信息时代,网络数据至关重要。网页抓取技术成为获取在线信息的重要手段。本文将对比分析两个流行的Python网页抓取库:Beautiful Soup和Scrapy,提供代码示例并阐述负责任的抓取实践。...
使用 Django 和 HTMX 创建待办事项应用程序 - 添加新待办事项的部分(待办.事项.应用程序.创建.添加...)
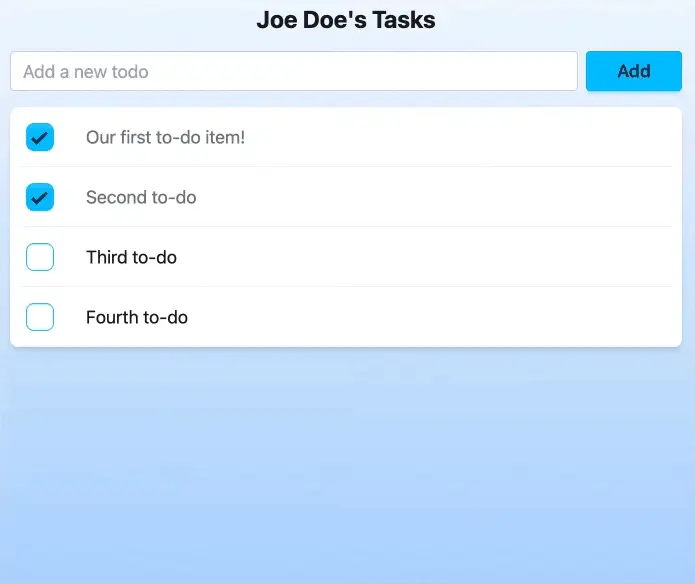
在本教程的第三部分,我们实现了待办事项的添加和删除功能。接下来,我们将添加一个表单,用于创建新的待办事项,并利用 htmx 和后端路由处理 post 请求。 表单效果如下: 处理 POST 请求 创...
最小里约简介(里约.最小.简介...)
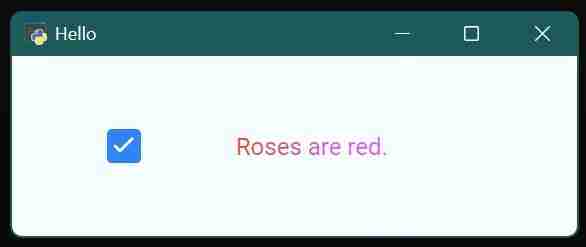
初探rio:一个轻量级python ui库 十一月初,Rio (https://www.php.cn/link/95009134498cf8501942c4970b0110ac) 发布公告,宣布推出这...
5 年内值得关注的令人兴奋的网络趋势(值得关注.令人兴奋.年内.趋势.网络...)

未来五年,Web 开发将迎来激动人心的变革。以下十个关键趋势值得关注: WebGPU: WebGPU 将彻底改变浏览器图形和计算处理方式,提供对GPU的低级访问,从而实现高性能渲染、数据处理和...
您的营销电子邮件最终会成为垃圾邮件吗?我们构建了一个工具来找出答案(您的.垃圾邮件.找出.构建.电子邮件...)

电子邮件营销的成功关键在于邮件送达收件箱而非垃圾邮件文件夹。本文将构建一个可验证邮件是否会被标记为垃圾邮件,并解释原因的工具。该工具将以api形式在线部署,方便集成到您的工作流程中。 垃圾邮件验证机制...
如何在 iMX 系列处理器上轻松安装和使用 Node-RED?(器上.轻松.安装.系列.如何在...)
随着物联网(iot)技术的快速发展,高效、稳定的开发平台已成为推动项目成功的关键。 imx6ul系列处理器凭借高性能、低功耗、紧凑的尺寸,成为众多物联网应用的理想选择。结合linux 4.1.15...
使用 Django 和 HTMX 创建待办事项应用程序 - 创建前端并添加 HTMX 部分(创建.待办.应用程序.事项.添加...)
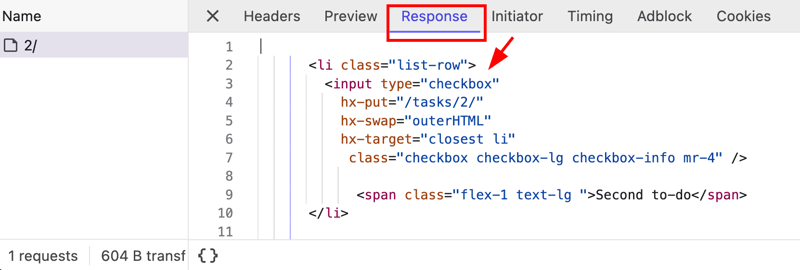
本系列文章的第三部分带您深入学习如何结合 htmx 和 django 构建动态待办事项列表。如果您错过了前两部分,建议先阅读。 模板和视图的创建 我们将创建一个基础模板和一个指向索引视图的索引模板,该...
使用 HTMX 和 Django 创建待办事项应用程序,部分无限滚动(待办.应用程序.滚动.事项.创建...)
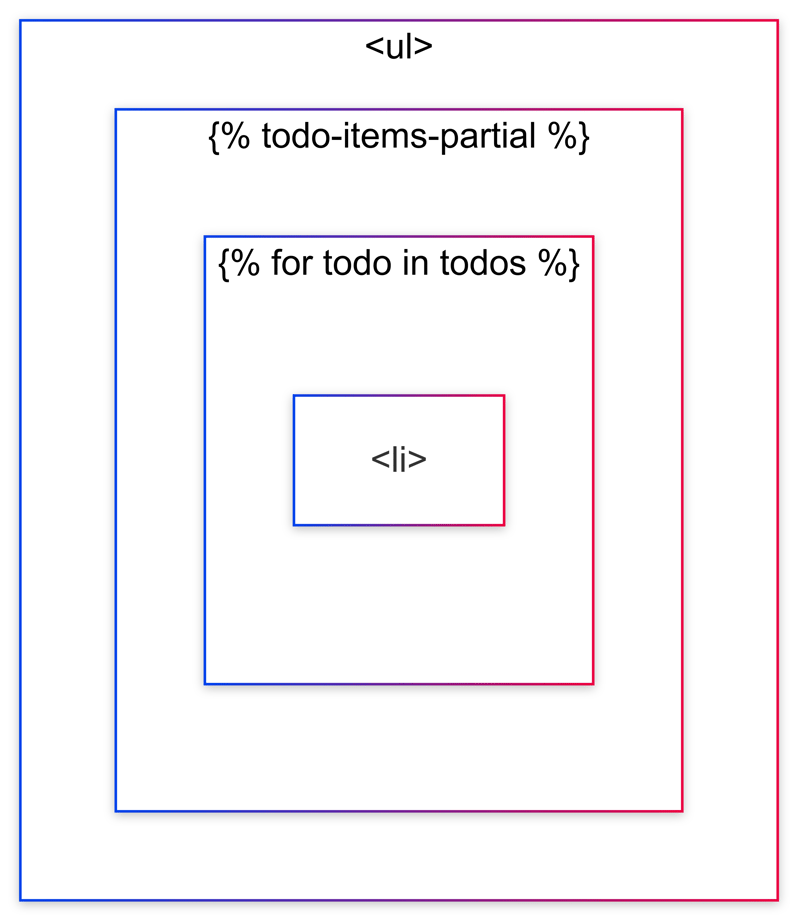
本教程是学习使用 django 和 htmx 实现无限滚动的第七部分。我们将遵循 htmx 文档,逐步实现待办事项列表的无限滚动功能。完整系列教程可在 dev.to/rodbv 查看。 更新部分模板以...
使用“加载更多”按钮抓取无限滚动页面:分步指南(分步.抓取.滚动.按钮.加载...)
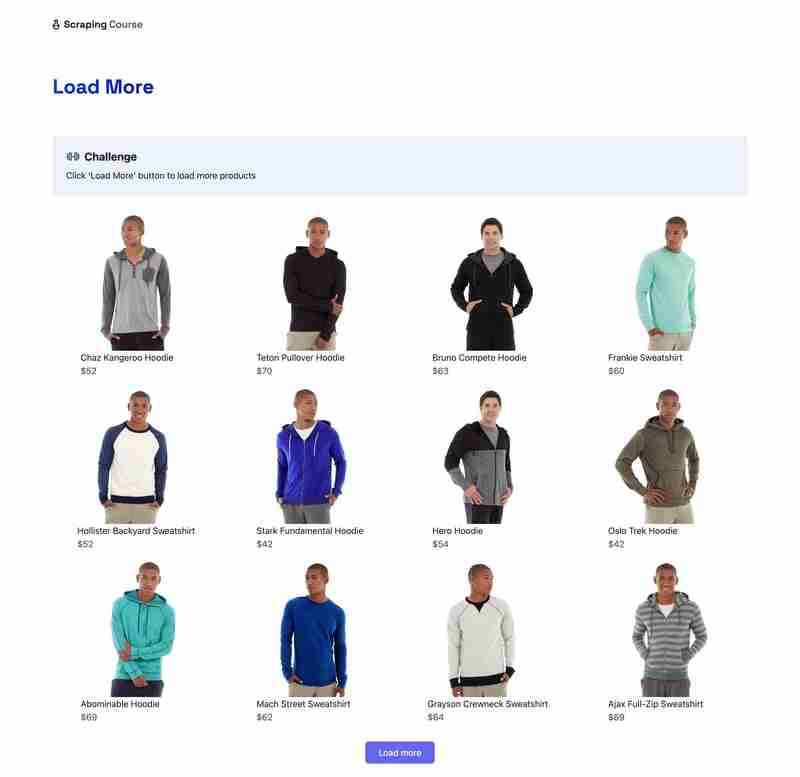
应对动态网页加载数据的挑战:自动化“加载更多”按钮的网页抓取 您的网页抓取工具是否在尝试从动态网页加载数据时卡住了?那些恼人的“加载更多”按钮让您抓狂吗?别担心,您并非孤身一人!许多网站如今都使用这些...