
从电路板到代码:作为一名多语言 Web 开发人员(和电气工程师)如何增强我的编程游戏(电路板.开发人员.作为一名.多语言.增强...)
精通多种编程语言的Web开发者,堪称编程界的异类。我们不仅掌握HTML和JavaScript,还像收集精灵宝可梦一样收集编程语言。Java?没问题。Python?当然。Rust?让我们一起挑战吧!如...
API 规划指南:代码优先 VS 设计优先方法(优先.规划.代码.指南.方法...)

如同建筑师先绘图纸再施工,API开发也遵循类似原则。本文将对比两种API规划方法:代码优先和设计优先,并指导您如何选择最适合的方法。我曾是代码优先的拥趸,直到发现设计优先的优势。设计优先强调在编码前...
使用 AWS 无服务器服务的比赛日事件通知(比赛.事件.服务器.通知.服务...)

本项目构建了一个实时的nba比赛比分警报系统,通过短信或邮件将比赛结果及时推送给订阅用户。系统利用amazon sns、aws lambda(python)、amazon eventbridge和nb...
如何使用 Python 从 IP 摄像机捕获实时视频流(捕获.如何使用.实时.摄像机.视频...)
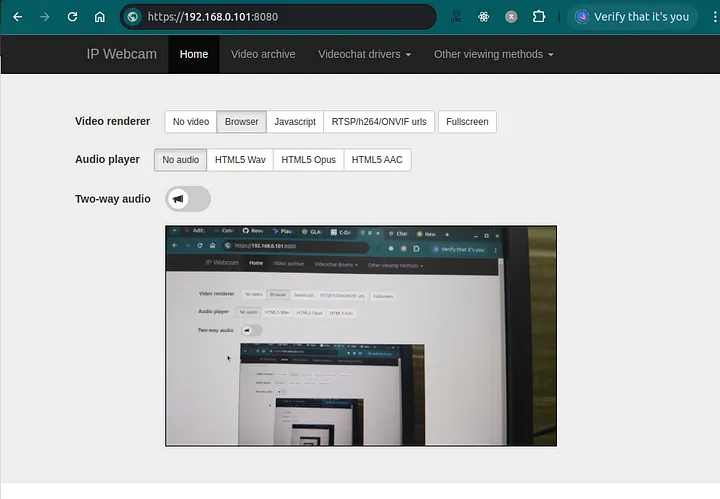
本文介绍如何使用 python 捕获和显示来自 ip 摄像头的实时视频流。我们将利用 requests 库获取图像 url,opencv 处理图像,以及 imutils 调整图像大小。最终程序将持续从...
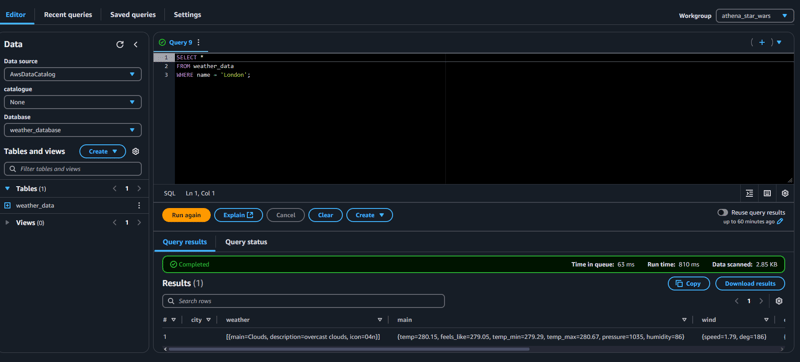
使用 AWS 和 OpenWeatherMap API 构建天气数据分析管道(管道.构建.天气.分析.数据...)
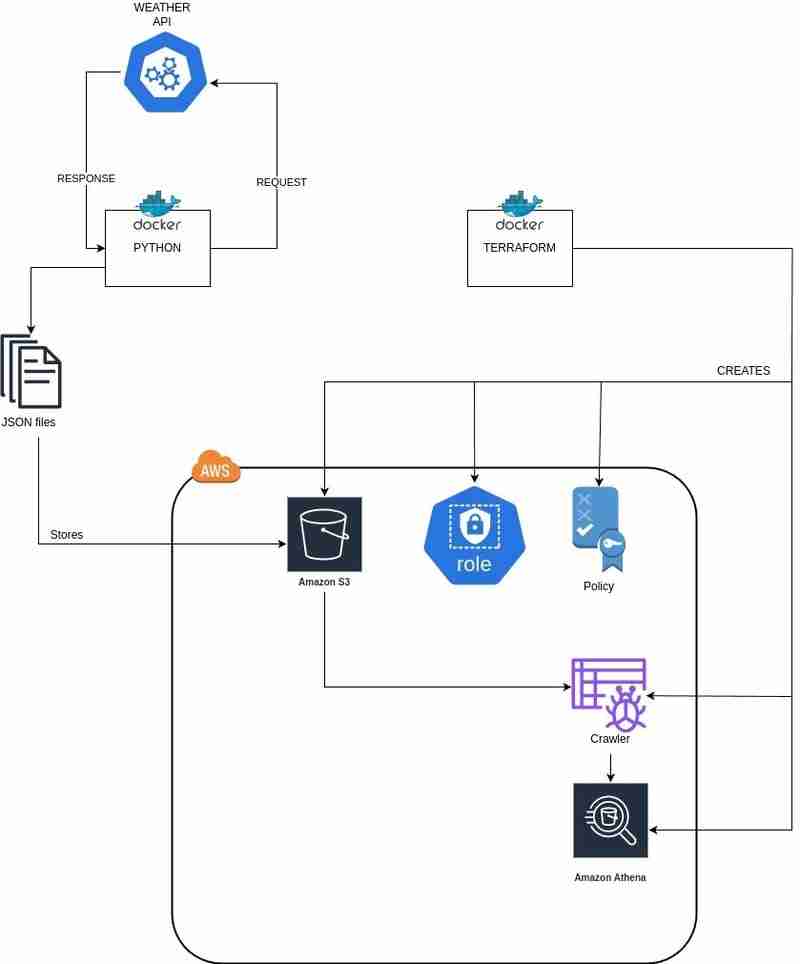
大家好!本文将指导您构建一个利用openweathermap api和aws服务进行天气数据分析的完整数据管道。该项目涵盖数据获取、s3存储、aws glue数据编目以及amazon athena查询...
如何将开源 Python 项目变成赚钱机器(开源.如何将.机器.赚钱.项目...)
想象一下:您是一位充满热情的开发人员,在一个解决实际问题的开源 python 项目上熬夜。你把它释放到野外,它就会获得牵引力。人们正在使用它、喜欢它并赞扬你的工作。但问题是——你不会从中赚到一分钱。这...
使用 Anthropic 的 Claude Sonnet 生成报告(生成.报告.Anthropic.Claude.Sonnet...)

Pilar,一家巴西房地产科技公司,联合创始人兼首席技术官Raphael分享了利用Anthropic Claude 3.5 Sonnet生成报告的经验,并比较了两种不同方法的优劣。Pilar为房地产...
可扩展的 Python 后端:使用 uv、Docker 和预提交构建容器化 FastAPI 应用程序:分步指南(分步.容器.应用程序.后端.构建...)
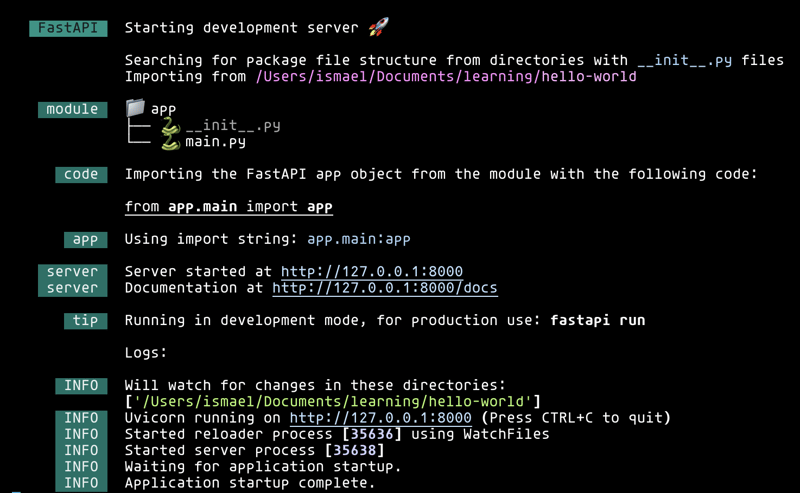
在当今容器化部署的世界中,高效构建和部署后端应用程序至关重要。 fastapi 已成为创建快速、高性能 api 的最流行的 python 框架之一。为了管理依赖关系,我们还可以利用 uv(包管理器)作...
PyTorch 中的 CenterCrop(PyTorch.CenterCrop...)
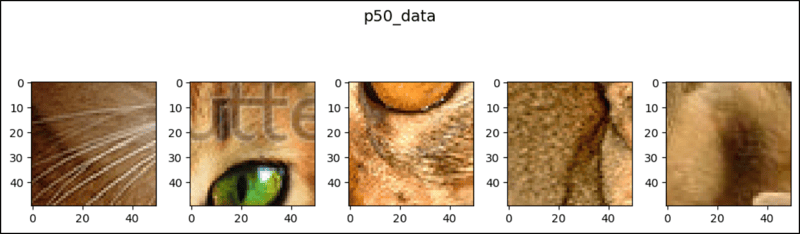
请我喝杯咖啡☕ *备忘录: 我的帖子解释了 oxfordiiitpet()。 centercrop() 可以裁剪零个或多个图像,以它们为中心,如下所示: *备忘录: 初始化的第一个参数...
Python 垃圾收集:您需要了解的一切(您需要.收集.垃圾.Python...)

一、Python垃圾回收机制详解 在计算机领域,垃圾回收(Garbage Collection, GC)是自动内存管理的关键技术,它负责回收程序不再使用的内存空间。这项技术极大地减轻了程序员的负担,...