
Docker 的开发:第 3 集(开发.Docker...)

本篇是 Ruby on Rails 应用 Docker 化系列的最终篇章。我们将学习如何在容器中执行日常任务。 运行 Rake 任务和 Rails 命令 运行 Rake 任务非常简单。镜像构建完成后...
快速而肮脏的文档分析:在 Python 中结合 GOT-OCR 和 LLama(肮脏.快速.文档.分析.LLama...)

让我们探索一种结合ocr和llm技术分析图像的方法。虽然这不是专家级方案,但它源于实际应用中的类似方法,更像是一个便捷的周末项目,而非生产就绪代码。让我们开始吧! 目标: 构建一个简单的管道,用于处理...
Django 的架构是怎样的?(是怎样.架构.Django...)
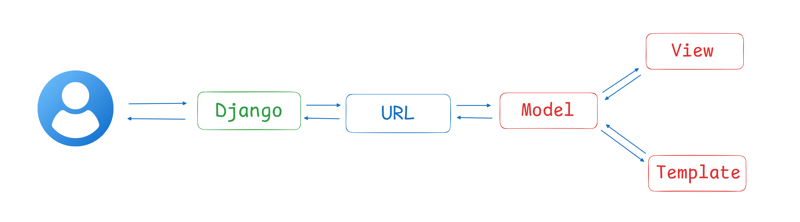
第一次被问到这个问题不是在我学习django的时候,而是在我学了它并申请实习之后。实习的时候,有人问过我这个问题。不幸的是,当时我不知道答案,但现在我知道了。 您创建的每个 Django 项目都遵循...
什么是机器学习?初学者指南(初学者.机器.指南.学习...)
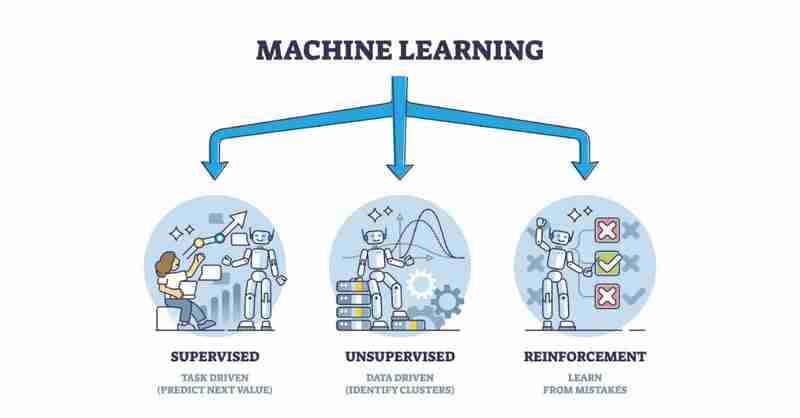
机器学习 (ml):开启人工智能时代的新篇章 机器学习是当今最激动人心、最具颠覆性的技术之一,它正在改变着各个行业的面貌,从个性化推荐到自动驾驶,其影响力日益显著。但机器学习究竟是什么?它如何运作?本...
需要机器学习方面的帮助(机器.学习...)
大家好, 我是机器学习的初学者,目前正在使用从 Kaggle 下载的心脏病 UCI 数据集。在探索数据时,我注意到有几列缺少值,我相信所有这些列对于分析都很重要。以下是我的数据集中缺失值的摘要:...
让您的 CLI 应用程序通过样式化输出流行起来(您的.应用程序.样式.输出.流行...)

告别枯燥乏味的命令行界面应用程序!虽然它们通常以简洁实用著称,但只需添加一些颜色、粗体文本和样式,就能彻底改变用户体验。Python 的 colorama 和 rich 库让个性化您的命令行工具变得...
用 igt 赚钱(赚钱.igt...)

每周挑战303 穆罕默德·S·安瓦尔 (Mohammad S. Anwar) 每周都会发布“每周挑战”,提供机会让大家为每周两次的任务编写解决方案。我的解决方案先用 Python 编写,再转换为 P...
Python 列表教程 Day2(教程.列表.Python.Day2...)

本节涵盖以下 Python 列表操作:矩阵转置、字符串旋转以及矩阵的各种统计计算(行总和、列总和、每行最大值/最小值、前导对角线总和)。 1. 矩阵转置 以下代码实现了矩阵转置: l = [[10,...
优化 HyperGraph 中的模块开发:极简方法(模块.优化.方法.开发.HyperGraph...)

本文分享在HyperGraph项目中优化模块开发的经验,重点是如何通过精简接口定义来降低复杂性。 挑战:模块化系统的复杂性管理 HyperGraph等模块化系统面临的挑战在于管理日益增长的复杂性。每...
为 HyperGraph 中的新模块设计上下文(上下文.模块.设计.HyperGraph...)

构建模块化系统,如何在灵活性和一致性之间取得平衡是一个关键挑战。本文分享我在 HyperGraph(我的开源 LLM 系统框架)中设计新模块上下文结构的经验。 挑战:新模块与现有模块的上下文差异 H...