
天元组,集合(天元.集合...)

元组:Python 中有序、不可变的数据结构 元组是 Python 中一种内置的数据结构,它以固定顺序存储多个项目。 一旦创建,元组的内容就不能更改。与列表类似,元组可以包含重复的值和混合数据类型...
【Python】B站视频评论和弹幕处理分析脚本(脚本.分析.评论.弹幕.视频...)

免责声明: 本脚本仅供个人学习和研究使用,禁止用于任何商业或非法用途。 概述 本Python脚本旨在辅助人文学科研究,特别是网络平台话语分析。它能够全面收集和分析B站视频的弹幕和评论数据,尤其适用于...
用于股票情绪分析的 Python 脚本(脚本.情绪.用于.股票.分析...)
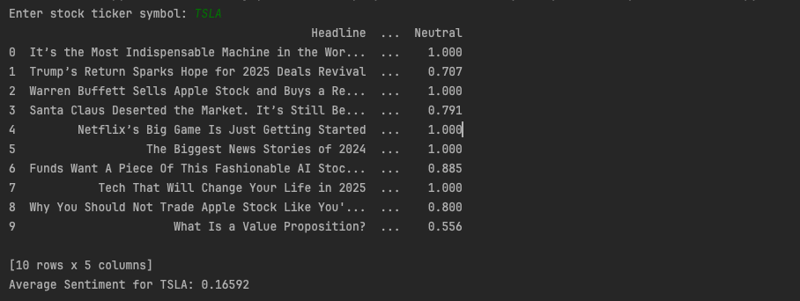
python在金融领域日益普及,其应用范围广泛,从基础计算到高级股票市场数据统计分析无所不包。本文将介绍一个python脚本,它展现了python在金融领域的强大功能,能够无缝整合数据、执行复杂计算并...
Python 的神奇方法(神奇.方法.Python...)

深入 Python 的 __new__ 方法 Python 中,创建新对象时会调用 __new__ 方法。该方法负责创建并返回一个新的类实例。当需要自定义对象创建过程时,例如实现单例模式、对象缓存或...
Python 中的排序数据结构(数据结构.排序.Python...)

Python 提供多种工具和库来处理排序数据结构,这些结构在保持数据顺序的同时优化搜索、插入和删除操作。本文将介绍以下几种排序数据结构: 堆 (Heap) 排序列表 (Sorted List) 排...
初学者 Python 项目:使用 OpenCV 和 Mediapipe 构建增强现实绘图应用程序(绘图.初学者.应用程序.构建.增强...)

本Python项目构建一个简单的增强现实(AR)绘图应用程序。利用摄像头和手势,您可以在屏幕上进行虚拟绘画,自定义画笔,甚至保存您的作品! 项目设置 首先,创建一个新文件夹,并使用以下命令初始化新的...
介绍 acolor:打印 ANSI 颜色代码的小实用程序(颜色代码.实用程序.打印.介绍.acolor...)
之前我分享过一个想法,想创建一个工具来方便地将 ANSI 颜色代码输出到控制台。 因为我正在改进我的 shell 提示符,所以觉得开发这个工具比不断搜索 shell 代码更高效。 于是,我创建了 a...
使用 ML 预测笔记本电脑价格(预测.笔记本.电脑价格.ML...)
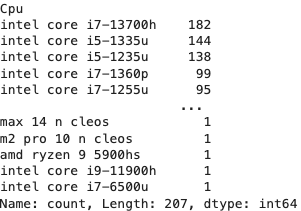
本文介绍了一个使用python从pccomponentes网站抓取数据,并构建机器学习模型预测笔记本电脑价格的项目。该项目解决了现有公共数据集数据过旧的问题,通过直接抓取网站数据获得更可靠、更新的数据...
日清单理解(清单.理解...)

列表推导式: 列表推导式是一种简洁优雅的Python语法,允许在一行代码中创建或修改列表。 示例1:打印包含字母“a”的水果(使用for循环): fruits = ["apple"...
Python 中的进程管理:并行编程基础(并行.进程.编程.基础.管理...)

并行编程能够让程序在多个处理器或内核上同时执行多个任务,从而更有效地利用处理器资源,缩短处理时间,提升性能。 想象一下,一个复杂问题被分解成多个独立的子问题,每个子问题再细分成更小的任务,然后分配...