
Java面试题宝典:如何应对那些常见的面试问题?(如何应对.宝典.面试题.面试.常见...)

Java面试题宝典 在求职过程中,面试官通常会考察候选者的Java基础知识和编程能力。本文为您收集了一系列Java面试题,涵盖了基础语法、面向对象、集合框架、多线程等多个方面,并附上详细答案。 Q:...
JDBC 连接错误:URL 中的数据库名称是否写错了?(错了.错误.名称.连接.数据库...)

jdbc 访问表时如何正确指定 url 在 jdbc 中,我们需要指定一个 url 来连接到数据库,其中包含了数据库类型、主机地址、端口号和数据库名称等信息。如果在访问表时收到连接错误,则可能是由于...
JDBC连接数据库时遇到“库名错误”如何解决?(如何解决.连接数据库.错误.JDBC...)
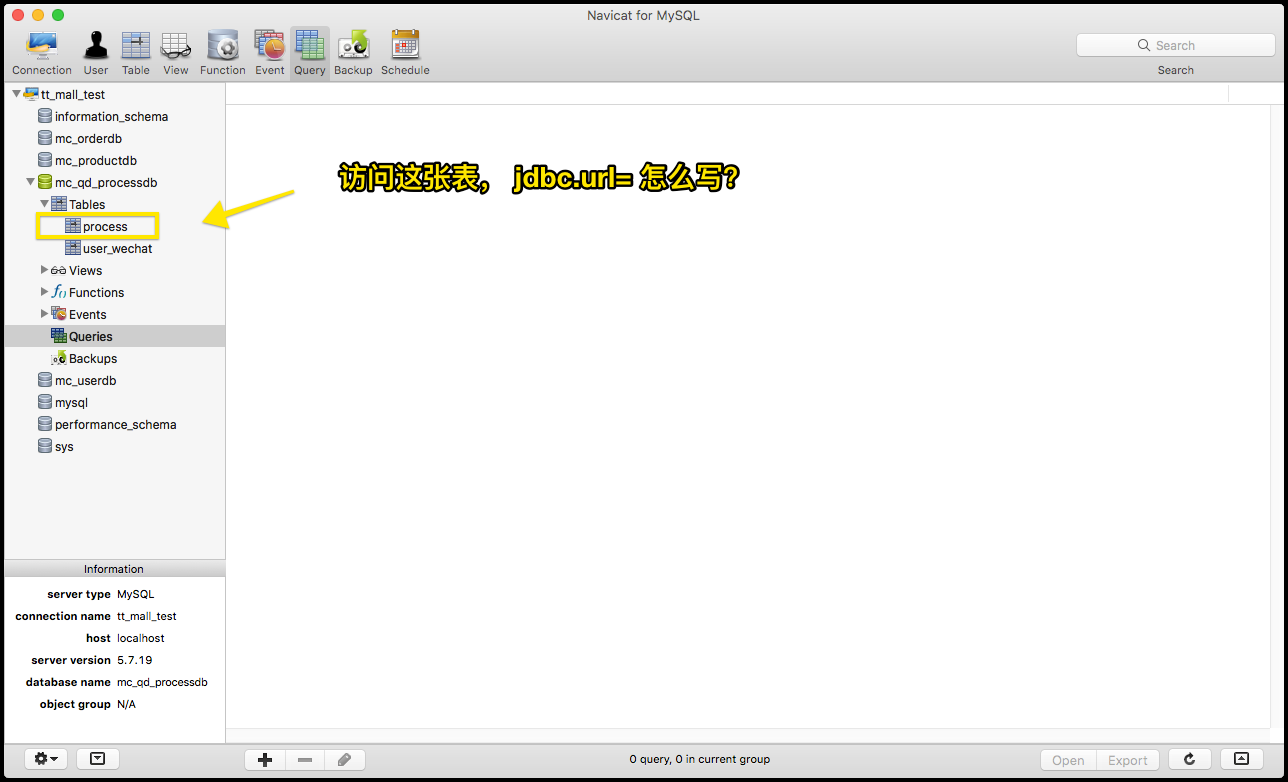
jdbc.url中访问到表 访问url时提示错误,原因是库名写错。 错误提示:本地数据库结构:解决方法: 将jdbc.url中的库名修改为图2中所示的正确库名,即可访问到表。 例如: jdbc.url...
Spring Boot 注解解释:您应该了解的基本注解(注解.解释.Spring.Boot...)

spring boot 通过抽象大部分样板配置,使开发基于 java 的应用程序变得异常容易。 spring boot 如此强大且用户友好的关键功能之一是它广泛使用注释。这些注释可帮助开发人员配置和...
面向 Java 开发人员的 MongoDB 性能调优(开发人员.面向.性能.Java.MongoDB...)

mongodb 是需要可扩展性和灵活性的应用程序的流行选择,但要充分利用其功能,性能调整至关重要。在这篇文章中,我们将探讨 java 开发人员优化查询、写入和正确配置的最佳实践,以确保您的 java...
OpenTelemetry:痕迹、指标、日志和行李(行李.痕迹.指标.日志.OpenTelemetry...)

随着分布式架构的进步和微服务的使用越来越多,传统的应用程序监控已经不够了。仅单独捕获指标或日志的工具无法提供复杂系统行为的完整视图。正是在这种背景下,OpenTelemetry 作为一个强大的解决方...
使用 OpenTelemetry 探索可观察性:上下文传播和分布式架构(上下文.分布式.架构.探索.观察...)

可观察性是确保复杂分布式系统成功的支柱之一。与对特定警报做出反应的传统监控不同,可观察性基于三个主要支柱提供了系统的广泛而深入的视图:指标、日志和跟踪)。这不仅可以识别问题,还可以识别其根本原因,这...
Spring Data JPA 中的高级查询技术(高级.查询.技术.Spring.Data...)

我们已经探索了 spring data jpa 的基础知识以及方法命名约定如何使查询变得简单。如果没有,我强烈建议您先关注该博客。在第二部分中,我们将深入研究更高级的查询技术,使您能够利用强大的组合、...
Java 函数中参数传递的多态性表现?(多态性.函数.传递.表现.参数...)

java 函数中的参数传递具有多态性,表现为以下两点:参数处协变:允许父类引用传递给子类类型的方法参数。返回值处协变:子类可以重写父类的方法并返回父类类型的返回值。Java 函数中参数传递的多态性 多...
python爬虫断点后怎么办(爬虫.断点.python...)

当python爬虫意外终止时,可通过以下步骤恢复断点:检查是否存在已保存的检查点。使用scrapy.extensions.checkpoint或scrapy_redis等第三方库实现断点恢复。手动恢复...