
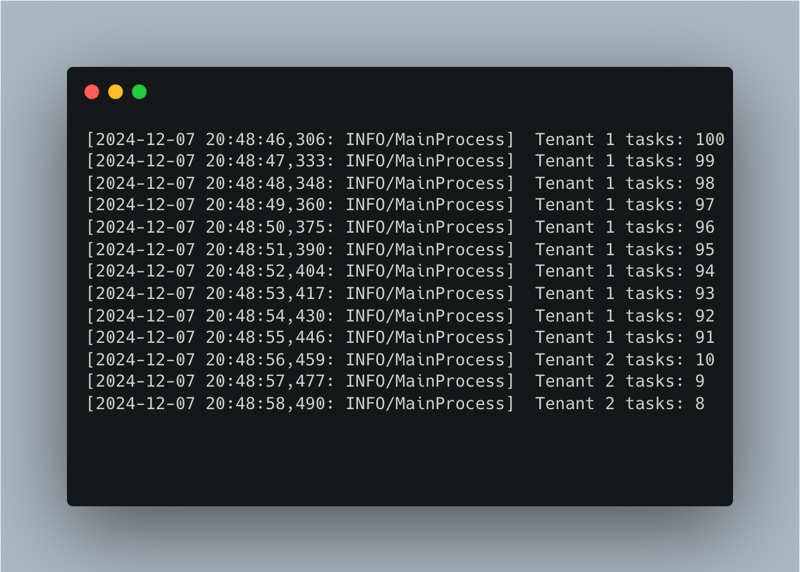
同步应用程序(应用程序.同步...)

单体应用程序是一种软件,其中系统的所有组件(例如用户界面、业务逻辑和数据库)都集成到一个统一的结构中。在此架构中,所有组件都作为一个应用程序的一部分运行。 单体应用程序的特点...
Faiss 与 RAG 的 sqlite(Faiss.RAG.sqlite...)

想要使用 faiss 进行本地 RAG 吗?好的,但是在哪里存储我的块(元数据)。 解决方案:将 faiss 与 sqlite(或任何其他 sql)连接。 如何:将向量保存在 faiss 中,将数...
可扩展软件架构的基本 Python 设计模式(架构.扩展.模式.设计.软件...)
作为一名拥有多年经验的 python 开发人员,我逐渐认识到设计模式在构建健壮且可扩展的软件架构方面的力量。在本文中,我将分享我对六种基本 python 设计模式的见解,这些模式在实际项目中不断证明...
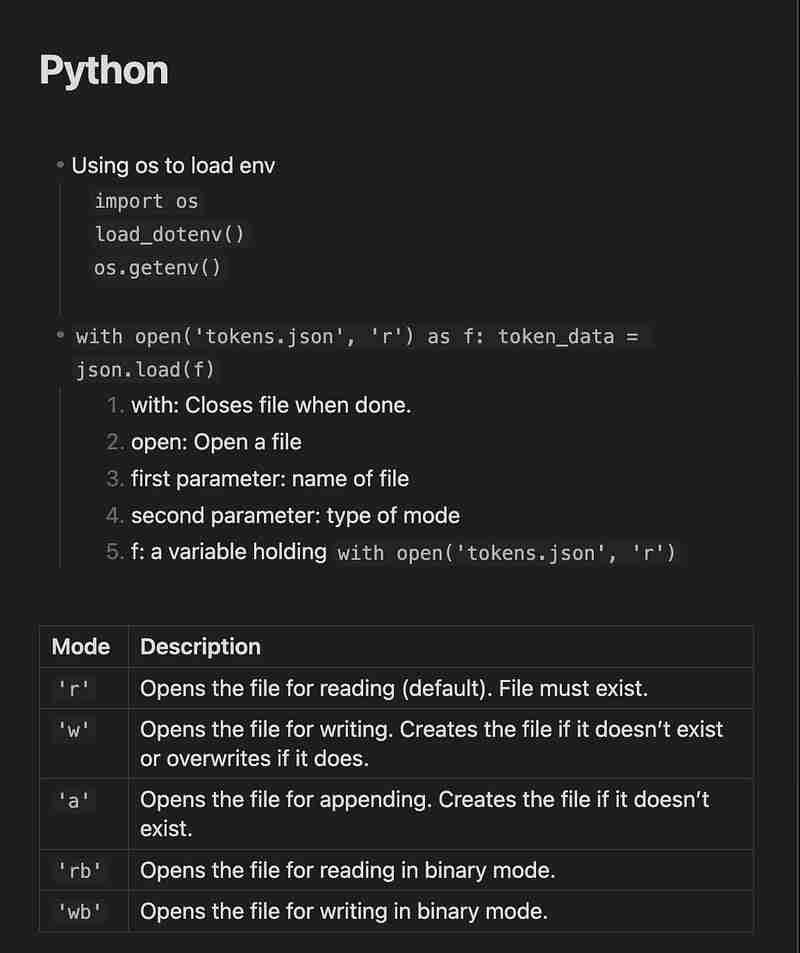
如何使用 Python 向文本文件的每一行添加引号和逗号(引号.逗号.如何使用.文本文件.添加...)

处理文本文件是编程中的常见任务,无论是数据清理、准备还是格式化。在本教程中,我们将探索如何使用 python 修改 .txt 文件,方法是在每行周围添加双引号 (") 并在末尾添加逗号 (,)。...
Jupyter Notebooks 就像电子表格一样学习两者(就像.电子表格.学习.Jupyter.Notebooks...)

电子表格是“商业软件的暗物质”:它们无处不在,它们是隐形的,并且它们将所有东西结合在一起。商业和财务在电子表格上运行;没有其他软件工具能够让这么多人为这么多不同的问题构建解决方案。在这种情况下,您必...
利用 LangChain 的 NLP 功能进行 AI 驱动的图探索,使用 Langchain 进行问答(问答.探索.利用.驱动.功能...)

编写复杂的SQL或图形数据库查询是否曾让您感到头疼?如果只需用简单的英语描述您的需求就能直接获得结果,那该多好?借助自然语言处理技术的进步,LangChain等工具不仅让这一切成为现实,而且操作起来...
用于强大应用程序的强大 Python 数据验证技术(强大.应用程序.验证.用于.数据...)
在构建可靠的 Python 应用时,数据验证至关重要。本文将探讨五种强大的数据验证方法,它们能有效减少错误,提升代码质量。 1. Pydantic:数据建模与验证的利器 Pydantic 简洁高效,...
PyApiGen Python 程序(程序.PyApiGen.Python...)
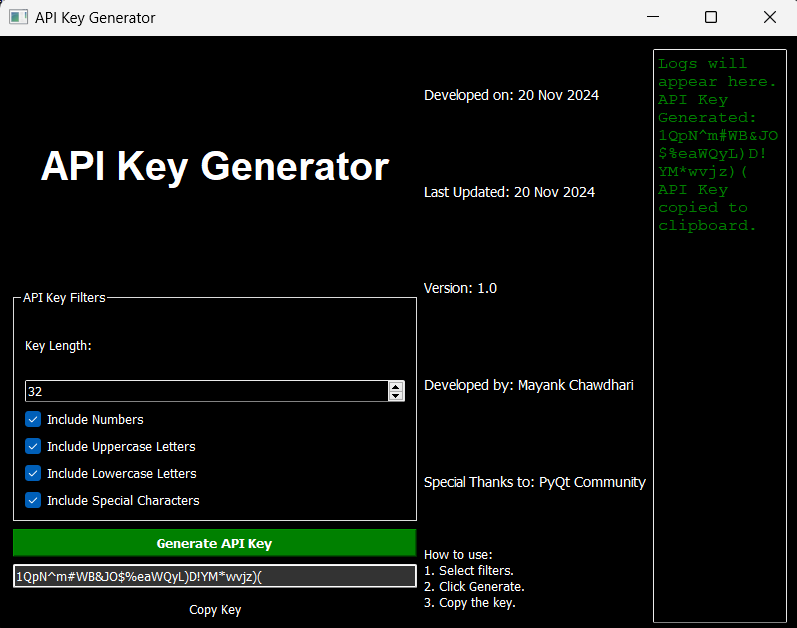
一款使用pyqt5构建的现代化、安全的api密钥生成器。该应用允许用户创建自定义的安全api密钥,增强安全性。其时尚的深色主题ui设计,为开发者提供流畅、高效的密钥生成体验。 主要功能: 自定义密...
释放您的创造力:使用开源 API 的端到端 Python 项目(您的.创造力.开源.端到.释放...)

想用Python和开源API构建令人印象深刻的项目吗?无论您是编程新手还是经验丰富的开发者,一个完整的应用程序都能充分展现您的技能,提升您的项目经验。本文将介绍六个创新项目创意,它们都以Python...
java入门零基础编程书和软件(入门.基础.软件.java.程书和...)

零基础学习 java 需选择合适的书籍和软件,推荐书籍有《head first java》《java for absolute beginners》和《thinking in java》,软件推荐 i...