
使用 AppSignal 在 Django 中查找并修复 N+ueries(修复.查找.AppSignal.Django.ueries...)
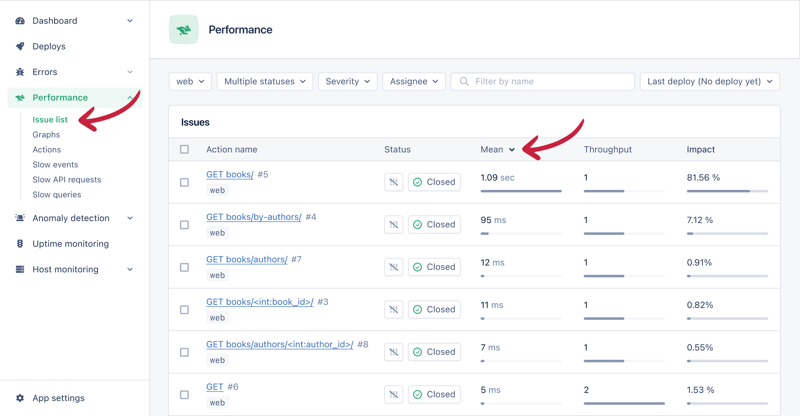
在本文中,您将了解 n 1 查询、如何使用 appsignal 检测它们,以及如何修复它们以显着加快 django 应用程序的速度。 我们将从理论方面开始,然后转向实际示例。实际示例将反映您在生产环...
FastAPI 速度背后的秘密(速度.秘密.FastAPI...)

fastapi 的速度优势源于其核心组件:starlette、uvicorn 和 pydantic 的强强联手。让我们深入了解这三个关键角色如何赋予 fastapi 优异性能: Starlette:高...
使用 Python 抓取 Google 搜索结果(搜索结果.抓取.Python.Google...)
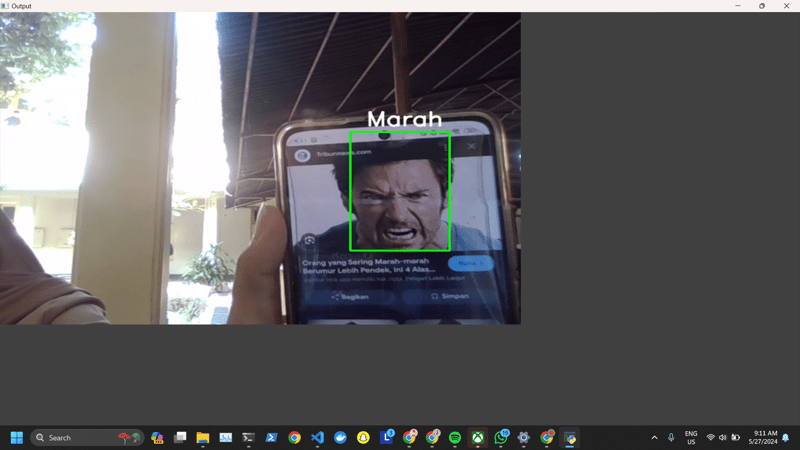
利用python高效抓取google搜索结果,洞悉数据趋势! Google每天处理超过85亿次搜索,占据全球搜索引擎市场91%的份额,蕴藏着巨大的数据价值,可用于SEO优化、竞争分析、潜在客户开发,以...
使用 Python 部署 Azure Functions:分步指南(分步.部署.指南.Python.Functions...)

Azure Functions是微软Azure提供的无服务器计算平台,允许开发者运行事件驱动的代码,无需管理服务器。本指南将逐步演示如何使用Python部署Azure Functions。 准备工作...
了解 Python 术语:模块、包、库和框架(术语.框架.模块.Python...)

学习编程语言时,理解专业术语至关重要。Python中的模块(module)、包(package)、库(library)和框架(framework)经常出现,但它们之间的区别并不总是清晰明了。本文旨在...
使用 DevTools 和 HAR 文件抓取数据(抓取.文件.数据.DevTools.HAR...)
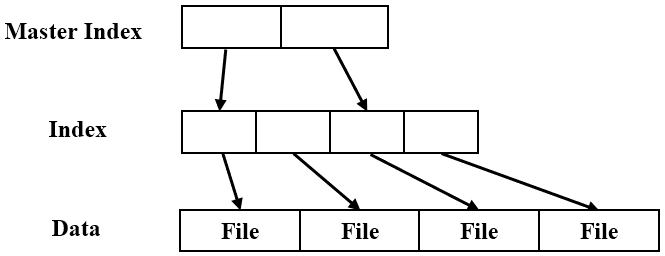
数据抓取:高效获取blinkit产品数据,助力应用开发 对于构建应用需要真实数据的开发者来说,数据抓取是高效获取信息的关键。本文将分享如何利用Chrome DevTools和HAR文件从Blinkit...
用于股票情绪分析的 Python 脚本(脚本.情绪.用于.股票.分析...)
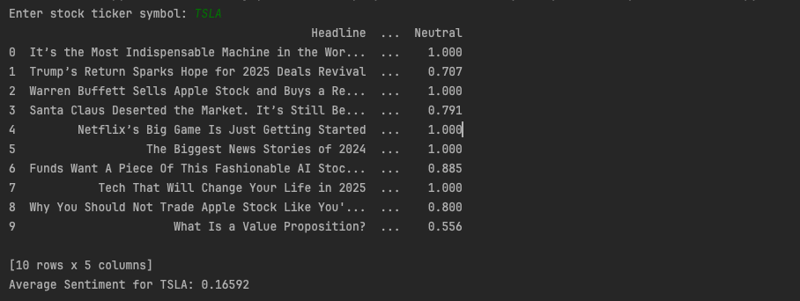
python在金融领域日益普及,其应用范围广泛,从基础计算到高级股票市场数据统计分析无所不包。本文将介绍一个python脚本,它展现了python在金融领域的强大功能,能够无缝整合数据、执行复杂计算并...
如何在 iMX 系列处理器上轻松安装和使用 Node-RED?(器上.轻松.安装.系列.如何在...)
随着物联网(iot)技术的快速发展,高效、稳定的开发平台已成为推动项目成功的关键。 imx6ul系列处理器凭借高性能、低功耗、紧凑的尺寸,成为众多物联网应用的理想选择。结合linux 4.1.15...
使用 Ngrok 将您的 Django 项目公开到 Internet(您的.公开.项目.Ngrok.Internet...)

Django 开发中遭遇 you're accessing the development server over https, but it only supports http. 错误?本文为您...
Flask 路由与 Flask-RESTful 路由(路由.Flask.RESTful...)
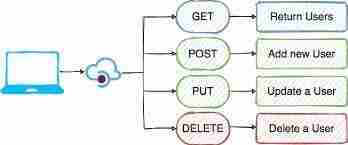
本文将从语法层面比较flask路由和flask-restful路由,帮助您理解两者在定义url路径、服务器资源和http方法上的差异。 什么是路由? 路由是客户端与服务器之间通信的通道,包含三个核心组...