
PHP 函数中递归的优势和局限有哪些?(递归.局限.函数.优势.有哪些...)

递归函数在 php 中的优势包括:解决复杂问题、简化代码和尾递归优化。然而,它也存在局限,如堆栈空间消耗、逻辑复杂性和额外开销。PHP 函数中递归的优势和局限 递归是一种特殊类型的函数,它可以调用自身...
华为将发布首款非凡大师折叠屏:华为Mate XT非凡大师官宣!三折手机来了(华为.非凡.大师)

9月3日消息,华为官方今天发文,正式官宣新机——华为mate xt非凡大师。从命名上来看,新机应该是一款折叠屏手机,也将是非凡大师系列的首款折叠屏手机。 结合近期爆料来看,华为Mate XT非凡大师应...
小米Redmi A3 Pro手机现踪迹:1300万主摄、4种颜色,有望9月发布(小米.踪迹.种颜色)
it之家 9 月 3 日消息,科技媒体 xiaomitime 昨日(9 月 2 日)发布博文,挖掘 mi code 代码库,发现了 redmi a3 pro 手机的踪迹,型号为 2409brn2cg,...
安兔兔8月安卓次旗舰性能榜出炉:天玑数量超过骁龙(旗舰.出炉.数量)

9月3日消息,安兔兔最新公布的8月份次旗舰性能排行榜中,骁龙7+ gen3处理器继续展现出强大的竞争力,稳居前两名。具体排名如下:1、一加ace 3v,以平均跑分高达142万分的成绩位居榜首。2、re...
消息称某厂新机配备 50Mp 大底大光圈主摄、单点超声波指纹,预计为 vivo X200 Pro(单点.光圈.新机)
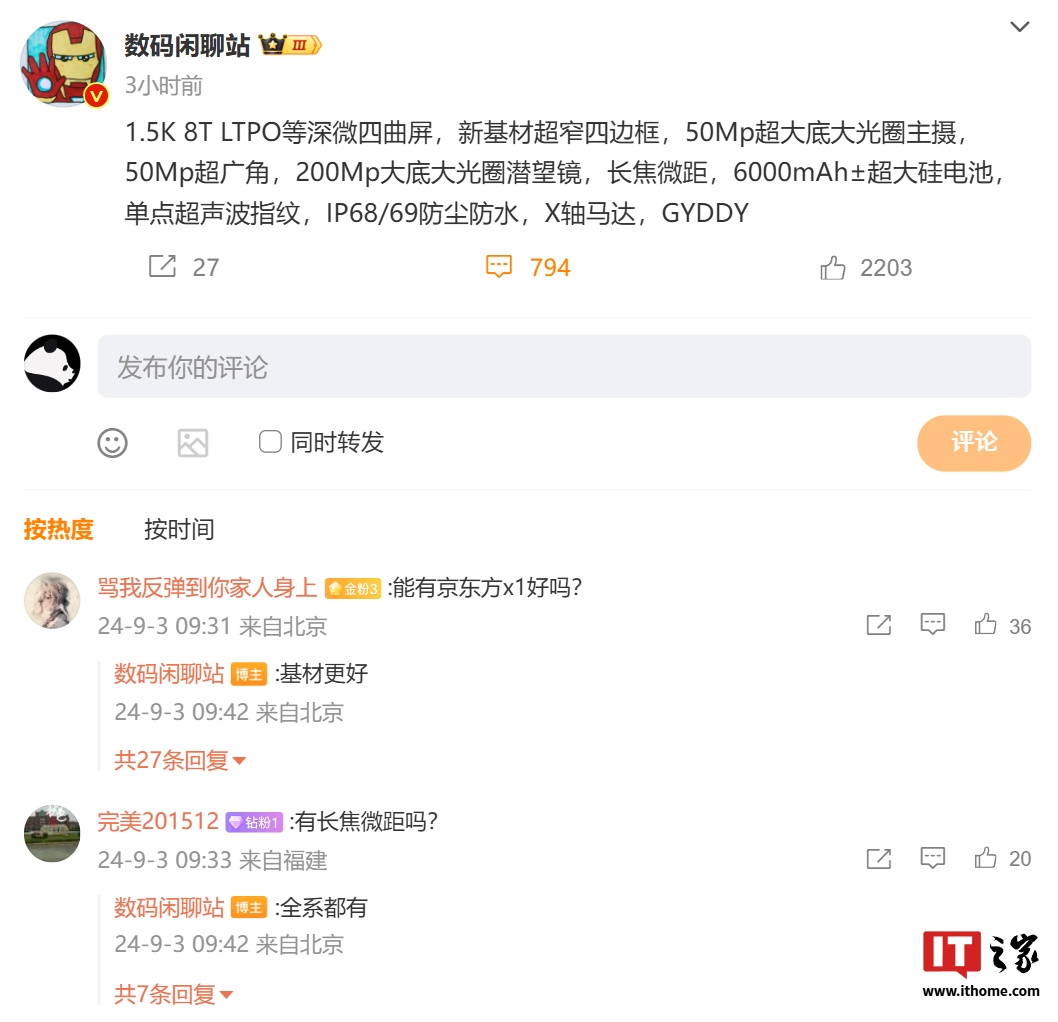
9 月 3 日消息,博主@数码闲聊站 今日发文爆料,某厂新机配备 50mp 大底大光圈主摄、单点超声波指纹等硬件配置,结合评论区讨论来看,该手机预计为 vivo x200 pro。 博主在评论区中回复...
博世洗衣机vs.西门子洗衣机(洗衣机.博世)

在如今快节奏的生活中,洗衣机已经成为家庭必备的家电之一。博世洗衣机和西门子洗衣机都是市场上备受欢迎的品牌,它们的性能和质量备受认可。然而,对于购买者来说,选择适合自己需求的洗衣机可能是个挑战。本文将比...
谷歌Pixel 9 Pro XL手机被曝屏幕问题:边角触控不灵,关闭输入法时无响应(边角.不灵.响应)

it之家 9 月 3 日消息,科技媒体 9to5google 昨日(9 月 2 日)发布博文,报道称多位谷歌 pixel 9 pro xl 智能手机用户反馈,手机边角屏幕存在点击反应迟钝、点击无效等问...
荣耀AI搜索正式上线!一键总结归纳 下拉桌面即刻体验(荣耀.下拉.归纳)

9月3日消息,今日荣耀官方宣布荣耀ai搜索正式上线,并宣称“答案直给,效率百倍”。用户只需要下拉桌面˃输入关键词˃点击顶部ai搜索按钮˃查看搜索结果(滑动页面查看大纲和脑图),就可以使用该功能。 1....
科技巨头同日对决!机构:华为首款三折叠手机将限制苹果销售(华为.同日.首款)

9月3日消息,进入9月,手机圈也终于热闹了起来,华为与苹果这两大科技巨头的大战也即将打响。北京时间9月10日凌晨1:00,苹果将举办秋季发布会,推出iphone 16系列。华为紧随其后,将在当天14:...
辟谣了!苹果官方否认微信不支持iPhone 16(辟谣.不支持.否认)

9月3日消息,日前,“苹果 微信”等多个相关话题登上微博热搜。有消息称,由于此前苹果要对微信生态开发者征收苹果税,微信可能不支持新的iphone16手机。对此,今日苹果官方客服回复称,“目前没有这样的...